
「一生懸命Webサイトを作ったのに、Googleで検索しても全然出てこない…」 そんなお悩み、抱えていませんか?
もしかすると、それは「クローラー」という検索エンジンのロボットが、まだあなたのサイトを見つけられていないからかもしれません。 Webサイト運営を始めたばかりの方にとって、SEOの仕組みは少し難しく感じることもありますよね。
でも、大丈夫です。 この記事では、検索エンジンの仕組みの第一歩である「クローラー」について、専門用語を使わずにわかりやすく解説します。 クローラーがサイトに来てくれる仕組みや、巡回を促すための具体的な方法まで、今日からできる対策を丁寧にお伝えしますね。
一緒に、検索エンジンに好かれるサイト作りを始めてみましょう。
クローラーとは?SEOにおける意味と役割

まずは、SEOの基本となる「クローラー」について、その正体をしっかりと理解しておきましょう。 名前だけ聞くと少し怖いイメージを持つかもしれませんが、実はWebサイトにとって非常に大切なパートナーなんですよ。 ここでは、クローラーの役割や種類について、やさしく解説します。
検索エンジンがWebサイトを巡回するロボットのこと
クローラーとは、Googleなどの検索エンジンがインターネット上の情報を収集するために使っている「巡回プログラム」のことです。
Web上のあらゆるリンクを辿りながら、世界中のWebサイトを自動で巡回(クロール)しています。 まるで「インターネットという広大な海を泳ぎ回って、新しい島(Webサイト)や変化を見つける探検家」のような存在だと思ってください。
この探検家があなたのサイトを見つけて情報を持ち帰ってくれない限り、検索結果には表示されません。 つまり、SEO対策のスタートラインは、このクローラーにサイトを見つけてもらうことにあるのです。
クローリングとインデックスの違い
よく混同されがちなのが「クローリング」と「インデックス」の違いです。 簡単に言うと、以下のような違いがあります。
- クローリング:ロボットがサイトを訪問し、文章や画像などの情報を「収集」すること
- インデックス:収集した情報を持ち帰り、検索エンジンのデータベースに「登録」すること
図書館で例えるなら、クローリングは「新しい本を見つけてくる作業」、インデックスは「その本を図書館の棚に並べて、検索カードを作る作業」にあたります。 まずは本(サイト)を見つけてもらわないと、棚(検索結果)には並ばないということですね。
代表的なクローラーの種類(Googlebotなど)
クローラーには、検索エンジンごとに様々な種類が存在します。 日本で最も利用されているGoogleのクローラーは「Googlebot(グーグルボット)」と呼ばれています。
以前はこのGooglebotにもパソコン用とスマートフォン用の2種類がありましたが、現在は仕組みが変わっているのをご存知でしょうか。
- Googlebot Smartphone:スマートフォンとしてサイトを見るロボット
2024年7月以降、Googleはパソコン用クローラーでの巡回を終了し、基本的にすべてのサイトをこのスマートフォン用クローラーが見回るようになりました。 (※求人検索など、一部の特殊な機能ではパソコン用が残る場合もあります)
以前から進められていた「モバイルファーストインデックス」という移行作業も完了していますので、現在はスマホ版のサイトが評価の基準です。 そのため、スマホで見やすいサイトを作ることが、クローラーにとっても親切な設計になるのですね。
検索順位が決まるまでの3つのステップとクローラーの関係
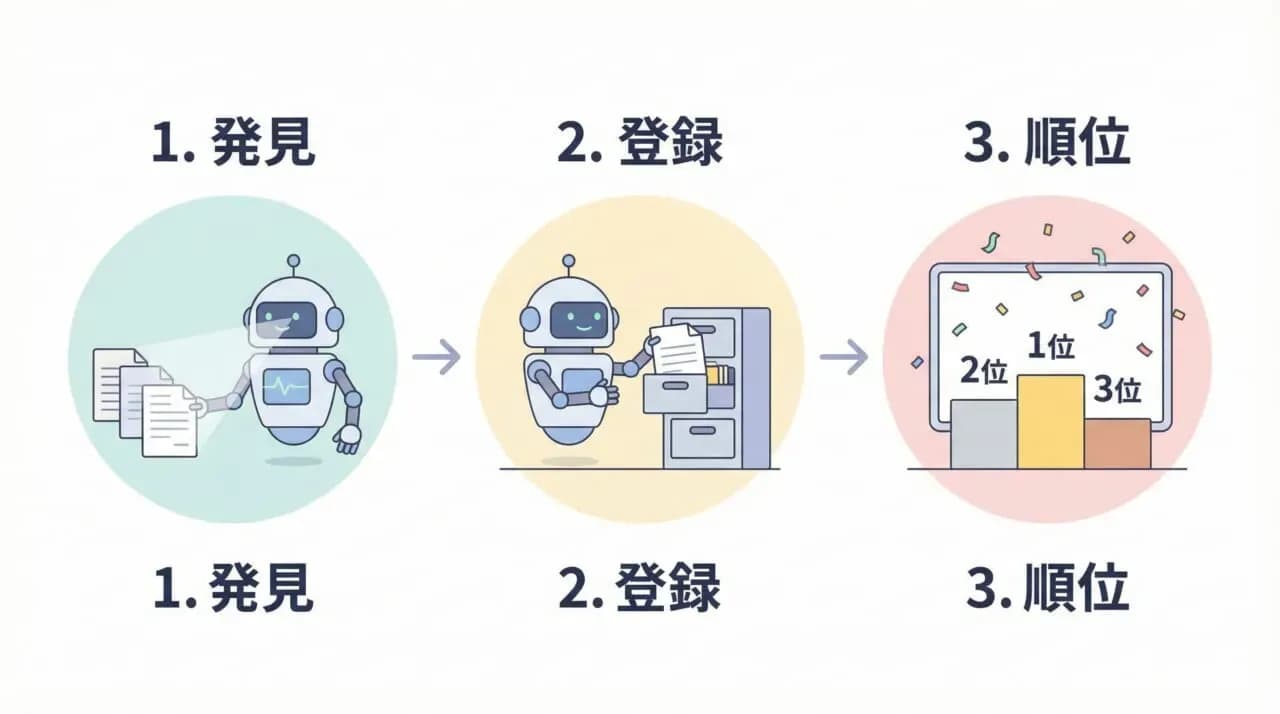
私たちが普段何気なく使っている検索エンジンですが、検索順位が決まるまでには明確な流れがあります。 クローラーがどのような動きをして、最終的に検索結果として表示されるのか、その3つのステップを見ていきましょう。 この流れを知ることで、SEO対策の全体像がつかみやすくなりますよ。
ステップ1:クローリング(情報の発見・収集)
最初のステップは、先ほどご紹介した「クローリング」です。 クローラーは、すでに知っているページからのリンクを辿ったり、サイトマップという案内図を参考にしたりして、新しいページや更新されたページを発見します。
この段階では、まだ検索結果には出ません。 あくまで「Googleがあなたのページを見つけた」という状態です。 そのため、リンクが繋がっていなかったり、どこからも紹介されていないページは、クローラーに見つけてもらうのが難しくなってしまいます。
ステップ2:インデックス(データベースへの登録)
クローラーが持ち帰った情報は、Googleの巨大なデータベースに整理・保存されます。これが「インデックス」です。 この時、Googleはページの内容を分析し、「何について書かれたページなのか」「有益な情報か」を判断します。
ただし、クローリングされたすべてのページがインデックスされるわけではありません。 内容が薄すぎたり、他のページと内容が重複していたりすると、「登録する価値が低い」と判断されてしまうこともあるのです。 インデックスされて初めて、検索結果に表示される準備が整います。
ステップ3:ランキング(検索結果の順位付け)
最後が「ランキング」です。 インデックスされたページの中から、ユーザーが検索したキーワードに対して最も適切で役立つと思われる順に並べ替えられます。
ここでは、200以上のアルゴリズム(評価基準)が使われていると言われています。 「クローラーに見つけてもらい(収集)、データベースに登録され(インデックス)、評価される(ランキング)」というこの一連の流れがスムーズに進むよう整えることが、SEO対策の基本なんですね。
クローラーが来ない・遅い場合に考えられる4つの原因

「サイトを公開したのに、いつまで経っても検索に出てこない…」 そんな時は、クローラーがうまく巡回できていない可能性があります。 なぜクローラーが来ないのか、あるいは遅いのか。そこには主に4つの原因が考えられます。 ご自身のサイトに当てはまるものがないか、チェックしてみてくださいね。
Webサイトやページを公開・更新したばかりである
Webサイトや新しい記事を公開しても、Googleがそれを検知するまでには少し時間がかかります(タイムラグ)。 インターネット上には膨大な数のページがあるため、クローラーがあなたの新しいページに順番に回ってくるまで待つ必要があるのです。
早ければ数時間で来ることもありますが、場合によっては数日〜数週間かかることも珍しくありません。 特に立ち上げたばかりのサイトは、まだクローラーの巡回ルートとして定着していないため、気長に待つ心構えも大切ですよ。
外部サイトからの被リンクが少なく発見されにくい
クローラーは、基本的に「リンク」を辿って移動します。 他のサイトからあなたのサイトへのリンク(被リンク)がない状態は、いわば「地図にない孤島」のようなもの。 クローラーが辿り着くための道がない状態です。
特に、信頼性の高い有名なサイトからのリンクは、クローラーにとって「太い道」のような役割を果たします。 誰からもリンクされていないと、発見される確率はどうしても低くなってしまうのです。
サイト内のリンク構造が複雑で辿り着けない
外部からのリンクだけでなく、サイト内部の構造も重要です。 トップページから何回もクリックしないと辿り着けない深い階層にあるページや、どのページからもリンクされていない「孤立ページ」は、クローラーにとって発見困難な場所です。
複雑に入り組んだ迷路のようなサイト構造だと、クローラーが途中で迷ってしまったり、全てのページを見ずに帰ってしまったりすることもあります。 シンプルで分かりやすい構造を心がけたいですね。
robots.txtなどでクローラーをブロックしている
意外とあるのが、設定ミスによって自分でクローラーを拒否してしまっているケースです。 「robots.txt」というファイルの設定で、クローラーに対して「立ち入り禁止」を命じてしまっていることがあります。
また、WordPressなどのCMSを使っている場合、「検索エンジンがサイトをインデックスしないようにする」という設定項目にチェックが入ったままになっていることも。 意図せずブロックしていないか、設定周りを一度確認してみることをおすすめします。
クローラーの巡回を促す具体的なSEO対策(クローラビリティの改善)

クローラーが来ない原因がわかったところで、次は「どうすれば早く来てもらえるか」という具体的な対策に移りましょう。 これを「クローラビリティの改善」と呼びます。 難しい技術が必要なものばかりではありません。初心者の方でも取り組みやすい順にご紹介しますので、ぜひ試してみてください。
Googleサーチコンソールで「インデックス登録をリクエスト」する
最も確実で即効性があるのが、Googleサーチコンソール(Search Console)を使う方法です。 これは、Googleに対して「新しいページを作ったから見に来て!」と直接招待状を送るような機能です。
URL検査ツールにURLを入力し、「インデックス登録をリクエスト」ボタンを押すだけ。 記事を公開したり更新したりした直後にこの作業を行う習慣をつけると、クローラーが巡回してくるスピードが格段に早くなりますよ。
XMLサイトマップ(sitemap.xml)を作成・送信する
XMLサイトマップは、検索エンジン向けの「サイト全体の地図」です。 サイト内にどんなページがあるのか、いつ更新されたのかをリスト化してクローラーに伝えます。
WordPressなどのCMSを使っている場合は、プラグインを使えば自動で生成・送信してくれることが多いです。 この地図をGoogleサーチコンソールに登録しておくことで、クローラーが効率よくサイト内を巡回できるようになり、ページの発見漏れを防ぐことができます。
内部リンクを設置してページ同士を網の目のようにつなぐ
サイト内のページ同士をリンクで繋ぐ「内部リンク」を充実させることも大切です。 関連する記事同士をリンクで繋ぐことで、クローラーがサイト内をスムーズに移動できるようになります。
例えば、「この記事を読んだ人はこちらもおすすめ」といった形で過去の記事を紹介してあげましょう。 これはクローラーのためだけでなく、読者にとっても便利な案内板になります。 サイト全体が網の目のように繋がっている状態が理想的ですね。
パンくずリストを設置してサイト構造をわかりやすくする
パンくずリストとは、ページの上部によくある「TOP > カテゴリ > 記事タイトル」といった表示のことです。 ユーザーに現在地を伝えるだけでなく、クローラーにとってもサイトの階層構造を理解する手助けになります。
パンくずリストにはリンクが含まれているため、クローラーが上の階層へ戻ったり、カテゴリ全体を把握したりするのに役立ちます。 もし設置していない場合は、ぜひ導入を検討してみてください。
ページの表示速度を改善して読み込み負荷を減らす
ページの表示速度も、実はクローラーの動きに影響します。 読み込みに時間がかかる重いサイトだと、クローラーが情報を読み取るのに時間がかかり、一度の訪問で巡回できるページ数が減ってしまう可能性があります。
- 画像のサイズを圧縮する
- 不要なプラグインを削除する
こうした対策で表示速度を上げることは、ユーザーの快適さだけでなく、クローラーにとっても「仕事がしやすい環境」を作ることにつながるのです。
質の高い被リンク(外部からのリンク)を獲得する
外部のサイトからリンクを貼ってもらう「被リンク」の獲得も、クローラーを呼び込む強力な方法です。 人気のあるサイトや更新頻度の高いサイトには、クローラーが頻繁に訪れています。
そうしたサイトからリンクが貼られていれば、その「道」を通ってあなたのサイトにもクローラーがやってきやすくなります。 役立つコンテンツを発信し、SNSでシェアするなどして、自然な形でリンクが増えるよう努めましょう。
クローラーのアクセス頻度や状況を確認する方法

対策を行ったら、実際にクローラーが来ているのか気になりますよね。 クローラーの動きは目に見えませんが、Googleが提供している無料ツールを使えば、その足跡を確認することができます。 ここでは、状況を確認するための2つの主要な方法をご紹介します。
Googleサーチコンソールの「クロール統計情報」を確認する
Googleサーチコンソールの「設定」メニューにある「クロール統計情報」を見ると、クローラーが過去90日間にどれくらいサイトに来てくれたかが分かります。
- クロールリクエストの合計数:クローラーがページを読み込んだ回数
- 平均応答時間:読み込みにかかった時間
このグラフが極端に下がっていたり、エラーが増えていたりしないか定期的にチェックしましょう。 右肩上がりや安定して推移していれば、サイトが健全に巡回されている証拠です。
URL検査ツールで特定のページのステータスを見る
個別のページについて詳しく知りたい場合は、同じくサーチコンソールの「URL検査」を使います。 調べたいページのURLを入力すると、「前回クロールした日時」や「クロールに使用したボット」などの詳細が表示されます。
もし「URLがGoogleに登録されていません」と表示された場合は、まだクローラーが来ていないか、インデックスされていない状態です。 その場合は、先ほどご紹介した「インデックス登録をリクエスト」を再度行ってみてくださいね。
不要なページへのクローラー巡回を制御する方法
ここまでは「来てもらう方法」をお話ししましたが、実は「来てほしくないページ」もあります。 例えば、会員限定ページやテスト環境、自動生成される質の低いページなどです。 重要なページを優先的に見てもらうために、不要なページへの巡回を制御する方法も知っておきましょう。
robots.txtファイルを作成してアクセスを拒否する
サイト全体や特定のディレクトリへのアクセスを拒否したい場合は、「robots.txt(ロボッツ・テキスト)」というファイルを使用します。 これは、クローラーに対して「ここは入らないでください」と伝えるための指示書のようなものです。
サーバーのルートディレクトリに設置し、Disallow: /admin/ のように記述することで、管理画面などの特定の場所へのクローラーの侵入を防ぐことができます。
ただし、設定を間違えると重要なページまでブロックしてしまう恐れがあるため、慎重に行いましょう。
nofollowタグを使用してリンク先への巡回を止める
特定のリンク先だけを辿らせたくない場合は、リンクタグに rel="nofollow" という属性を追加します。
これはクローラーに「このリンク先は辿らなくていいですよ(または、私のサイトとは関係ありません)」と伝える合図です。
例えば、信頼できないサイトへのリンクや、有料広告のリンクなどに使用します。 これにより、クローラーが無駄な寄り道をせず、あなたのサイト内の重要なページを集中して巡回してくれるようになります。
まとめ

クローラーについて、その仕組みから対策まで詳しく見てきましたが、いかがでしたか?
今回のポイントを簡単におさらいしましょう。
- クローラーは探検家:あなたのサイトを見つけて情報を持ち帰る大切なパートナー
- 3つのステップ:発見(クロール)→登録(インデックス)→順位付け(ランキング)
- 待つだけではダメ:サーチコンソールでのリクエストや内部リンクの整備で、能動的に呼び込むことが大切
- 定期的な確認:クローラーがちゃんと来ているか、ツールを使ってチェックする
「検索順位を上げたい!」と思うと、どうしてもキーワードやコンテンツの中身ばかりに目が行きがちです。 でも、どれだけ素晴らしい記事を書いても、クローラーに見つけてもらえなければ、誰の目にも留まりません。
まずは、クローラーが巡回しやすい「道」を整えてあげること。 それが、Webサイトを多くの人に見てもらうための、最初の一歩であり、一番の近道です。 今日ご紹介した対策を一つずつ試して、あなたのサイトをクローラーにたくさんアピールしてみてくださいね。
クローラーについてよくある質問

最後に、クローラーについて初心者の方がよく疑問に思う点をQ&A形式でまとめました。 疑問を解消して、スッキリした気持ちでサイト運営に取り組んでくださいね。
- クローラーはどのくらいの頻度で来ますか?
- サイトの更新頻度や評価によって異なります。毎日来るサイトもあれば、数週間に一度のサイトもあります。定期的に記事を更新することで、クローラーの訪問頻度を高めることができます。
- スマホ対応していないとクローラーは来ませんか?
- 来ますが、評価が下がる可能性があります。現在はスマホ版のクローラーがメインで巡回しているため、スマホで見にくいサイトはSEO的に不利になることが多いです。
- インデックス登録リクエストは何度やってもいいですか?
- 基本的には一度で十分です。同じページに対して短期間に何度もリクエストを送っても、処理が早くなるわけではありません。記事を修正・更新したタイミングで送るのがベストです。
- クローラーの巡回を拒否すると検索順位に影響しますか?
- 重要なページを拒否してしまうと、検索結果に出なくなるため影響します。逆に、質の低いページ(重複コンテンツなど)を拒否することで、サイト全体の評価を保つ効果が期待できます。
- 画像もクローラーは見ていますか?
- はい、見ています。ただし、画像の内容までは完全に理解できないこともあります。そのため、
alt属性(代替テキスト)を設定して、どんな画像なのかを文字で説明してあげることが大切です。
- はい、見ています。ただし、画像の内容までは完全に理解できないこともあります。そのため、
監修者紹介
