
簡単に説明しますと、構造化データはHTMLで記載されたページの構成やテキストの意味合いなどを、よりわかりやすく説明するためのデータを指します。
以下より、詳しく解説していきます。
構造化データとは
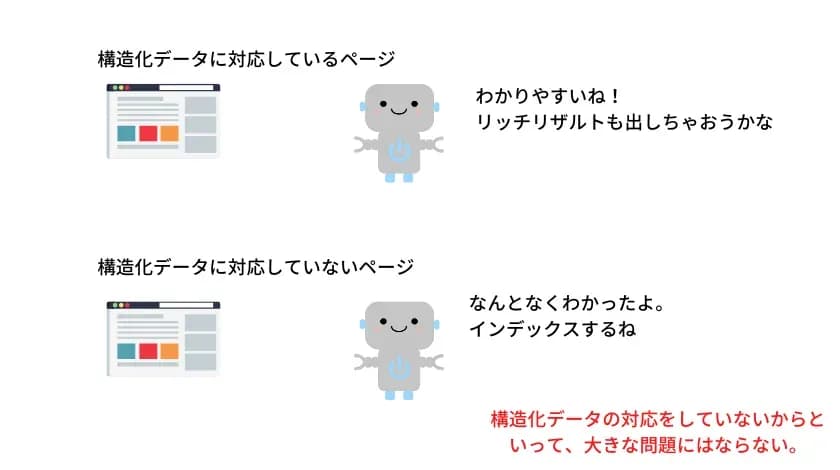
構造化データとは、HTMLで記載されたデータ(情報)を検索エンジンに対して、具体的に伝えるためのタグづけしたデータのことを指します。
例えば、次の文章を見てみましょう。
「ココログラフは渋谷にあり、SEO対策を主な業務内容としております。ご相談は、050-1748-9550よりご連絡ください。」
なんの変哲もない文章ですが我々は脳の働きから、文章の中身を細かく分析しなくても、自然と多くの情報を読み取っています。「渋谷」は日本の東京都にある地名、「050-1748-9550」は電話番号、などなど。
しかし、検索エンジンはテキストの意味を具体的に理解することが容易ではありません。「ココログラフ」は会社名、「渋谷」は会社の所在地、「050-1748-9550」という数字は電話番号などと、テキストの意味を正確に伝える必要があります。
※対応していないからといってインデックスされないなど、クリティカルな問題になることはありません。
セマンティックWebに基づいた考え方
上記のように、文字列を文字列として扱うだけでなく、ひとつひとつの意味合いや文脈を検索エンジンにしっかり理解させようとする考え方を、セマンティックWebといいます。
URLでよく目にする、「WWW(World Wide Web/ワールドワイドウェブ)」を考案した、W3CのTim Berners-Lee(ティム・バーナーズ・リー)博士によって提唱された概念です。
検索エンジンにわかりやすくすることで、リッチリザルトの表示も期待ができ、ユーザービリティも向上します。
※リッチリザルトとは、検索結果においてサイトをクリックせずとも、検索キーワードの答えが表示されているテキストのこと。(下記画像参照)
構造化データにまつわるボキャブラリーとシンタックスとは?
構造化データを考える際に、ボキャブラリーとシンタックスというフレーズが出てきます。それぞれ簡単に解説をしておきます。
ボキャブラリーとは
構造化データの値を定義する・マークアップする物事を定義するもとのことを、ボキャブラリーといいます。
代表的なボキャブラリーに、Schema.orgがあります。GoogleやMicrosoft、ヤフーなどの企業が共同で運営していおり、Googleも構造化データに際してSchema.orgを使用することを推奨しています。
人の名前を表す際は、「name」を使用する、住所を表す場合は「address」を使用するなどを定めているのがボキャブラリーということになります。
シンタックスとは
構造化データを記述する仕様・書き方のことをシンタックスといいます。
記述されているプロパティの論理構造を示すために必要なもので、グーグルがサポートしているシンタックスは、
- JSON-LD
- RDFa
- Microdata
の3つになります。
それぞれの記述例についても簡潔に示しておきます。
JSON-LD
1<script type="application/ld+json">2 {3 "@context": "https://schema.org/",4 "@type": "Recipe",5 "name": "チョコレート",6 "author": {7 "@type": "Person",8 "name": "中村一浩"9 },10 "datePublished": "2022-08-23",11 "totalTime": "PT120M"12 }13</script>
RDFa
1<div vocab="https://schema.org/" typeof="Recipe">2 <span property="name">チョコレート</span>3 By <span property="author">中村一浩</span>,4 <meta property="datePublished" content="2022-08-23">2022年8月23日5 Prep Time: <meta property="totalTime" content="PT120M">120分6</div>
Microdata
1<div itemscope itemtype="https://schema.org/Recipe">2 <span itemprop="name">チョコレート</span>3 By <span itemprop="author">中村一浩</span>,4 <meta itemprop="datePublished" content="2022-08-23">2022年8月23日5 Prep Time: <meta itemprop="totalTime" content="PT120M">120分6</div>
それぞれ簡潔に書いてみました。
microdataやRDFaは、表示されるテキストに対して直接マークアップを行います。
一方で、JSON-LDは表示されるテキストとマークアップを別々に記述しています。
JSON-LDはWebページに表示するテキストとは別で構造化データを記述するため、運用管理が容易になります。GoogleもJSON-LDのを推奨しているので、よほどのこだわりなどがなければJSON-LDで記述しておきましょう。
構造化データを実装(マークアップ)しておくメリット
冒頭に、「構造化データを実装していなくても大きな問題にはならない」とお伝えしました。
「書かなくても良いなら別に小難しいことをしなくても良いのでは?」とお考えになるかもしれませんが、できることは全てやるのは、真のSEO担当者です。メリットを知ればきっと、あなたは構造化データを入れずにいられなくなるかも...。
メリット1.リッチリザルト・リッチスニペットの表示が期待できる
先ほどの画像のように、検索結果において情報が多く表示されることを指します。
他にも、構造化データを実装することで、下記画像のデジ研さんのページのようにアコーディオンが表示されるケースもあります。

構造化データを実装することで、必ず表示されるわけではありませんが、こうして目に見える効果も期待することができます。
リッチリザルト・リッチスニペットが表示されることで、ユーザーのクリック率が上がるチャンスも期待できます。
メリット2.検索エンジンにサイトの内容を深く理解してもらえる
何度もお伝えしているように、構造化データの実装は検索エンジンに向けて作業です。
何も行っていないサイトよりも、構造化データをしっかり反映しているサイトの方が、検索エンジンにとってもわかりやすいですよね。
当然、検索エンジンに情報を深く伝えることができれば、検索結果に良い影響をもたらす可能性があります。
構造化データにまつわるデメリット
反対に構造化データにまつわるデメリットについてもみておきましょう。
デメリット1.なんだかんだ難しい
専門知識が必要になるため、どうしても難しくなります。
構造化データの書き方もお決まりを理解しておかないと、HTMLっぽい部分もあり、同じように書いてはいけないルールもあり...と少し厄介です。
デメリット2.時間がかかるケースがある
コピペで行うケースであればともかく。記述した内容が間違っていないかどうかを、確認する作業などを踏まえると実装までには少し時間を要します。
また、エラーが出た際に「何が間違っているのか?」を理解するまでに時間がかかるケースもあります。
慣れるまでは、構造化データの記述は時間がかかるでしょう。
構造化データを実装(マークアップ)する方法
では、どのように構造化データを実装すれば良いのでしょうか?指定のファイルに実装したり、WordPressの場合はプラグインでコンパクトに対応できるケースもあるので、それぞれ解説していきます。
個別ファイルに直接実装する場合
一般的なschema.orgのボキャブラリー(定義)と、JSON-LD(シンタックス/記述方法)を用いた方法で解説します。
ボキャブラリーやシンタックスについて、ここではGoogleの推奨している、JSON-LD/schema.orgの形式を押さえておけばOKです。
会社情報をマークアップしてみます。
1<script type="application/ld+json">2{3"@context": "https://schema.org",4"@type": "LocalBusiness",5"name": "株式会社ココログラフ",6"image": "https://www.sample.co.jp/images/logo.png",7"telephone": "050-1748-9550",8"address":{9"@type":"PostalAddress",10"streetAddress":"2-19-15",11"addressLocality":"渋谷区",12"addressRegion":"東京都",13"postalCode":"150-0002",14"addressCountry":"JP"15}16}17</script>
挿入するファイルのheadタグ内でもbodyタグ内でも記載箇所は問題なく、scriptタグで囲みます。
構造化データマークアップ支援ツールを用いる場合
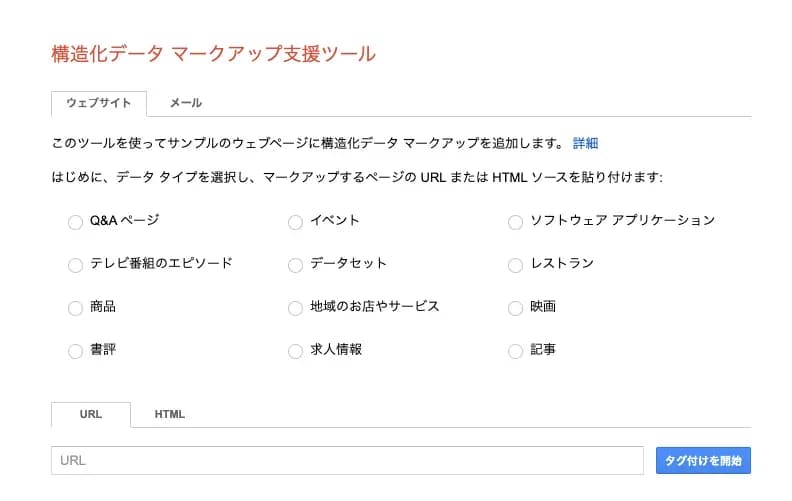
適用できる種類が限られてきますが、簡単な操作で使用できる構造化データマークアップ支援ツールというGoogleの提供しているツールがあります。
構造化データをマークアップしたい箇所にチェックを入れ、対象となるページのURLをペーストして「タグづけを開始」を押しましょう。
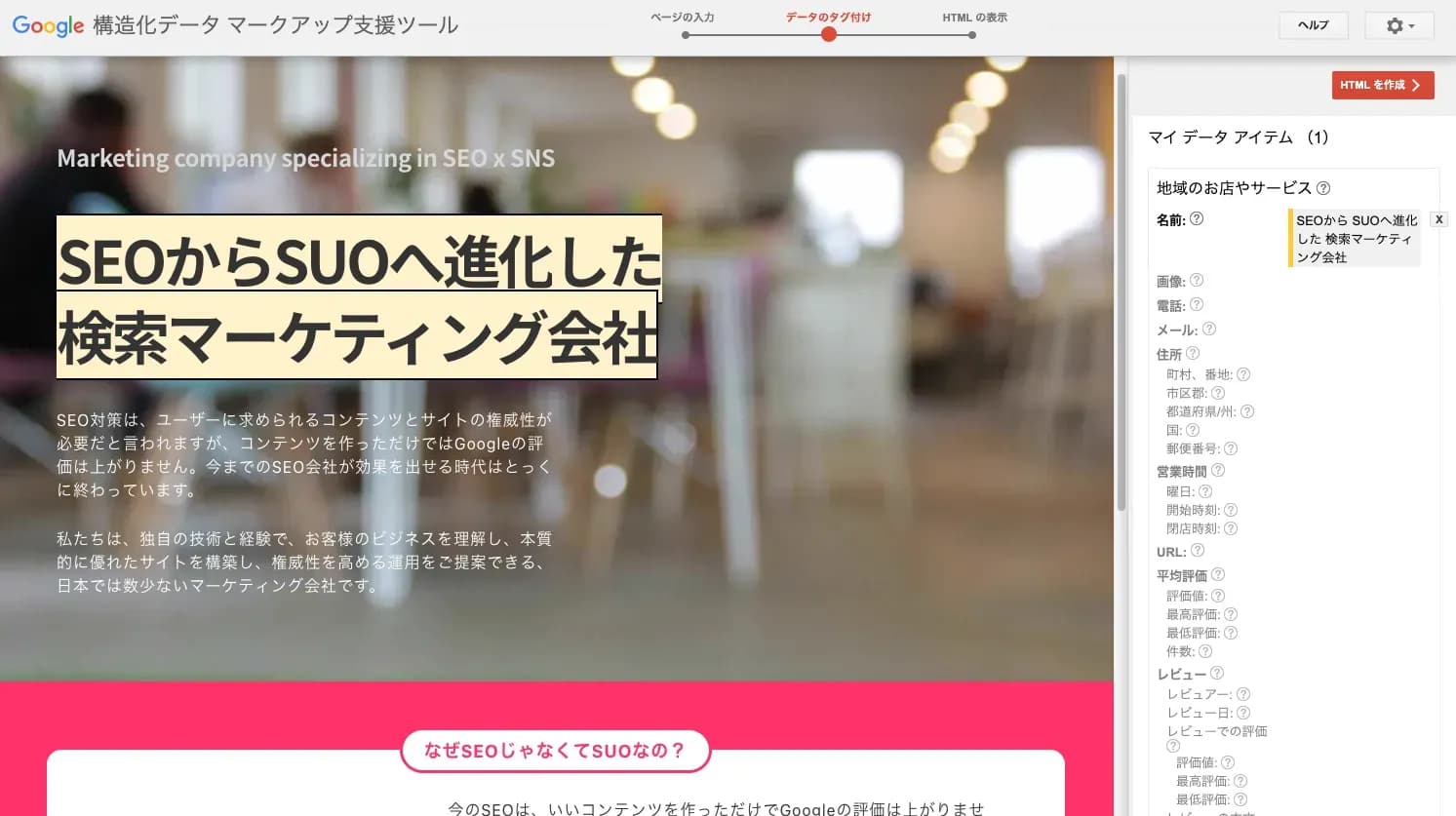
マークアップしたい箇所をドラッグすると、
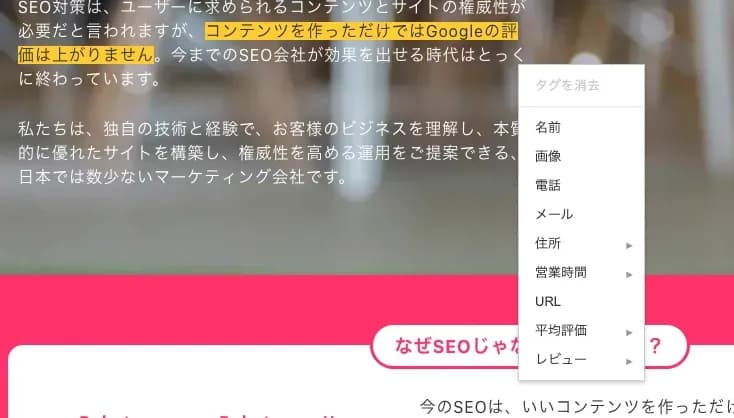
何に関する情報を付与するか選択肢が出てきます。
一通り、選択が終わったら右上の「HTML」を作成を押しましょう。
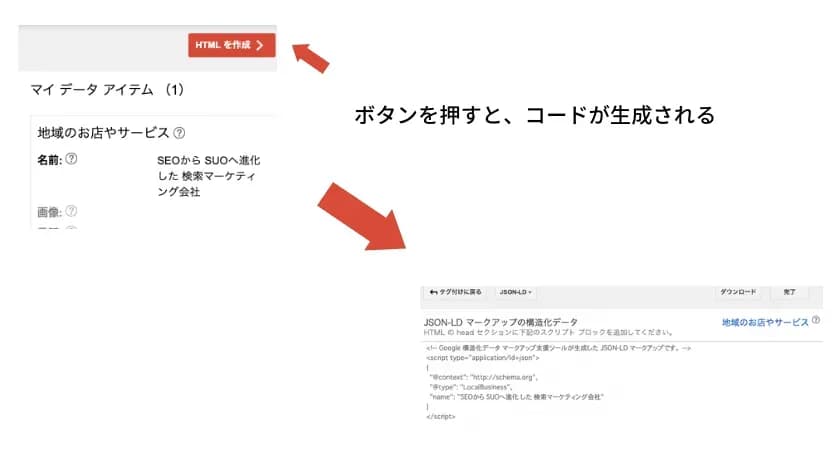
すると、選択した内容の構造化データを生成してくれるので、コピペして対象のページに貼り付けるだけです。
WordPressの場合(プラグインで実装)
コードを触ったり、何やら難しい印象を持ちやすいのが構造化データです。
WordPressを使用されている場合は、プラグインを使用するのも良いですね。
個別に挿入できる構造化データ用のプラグインも多くありますが、大抵のSEOプラグインでは構造化データの挿入まで対応が可能です。
弊社がお奨めしているのは、「Rank Math」です。
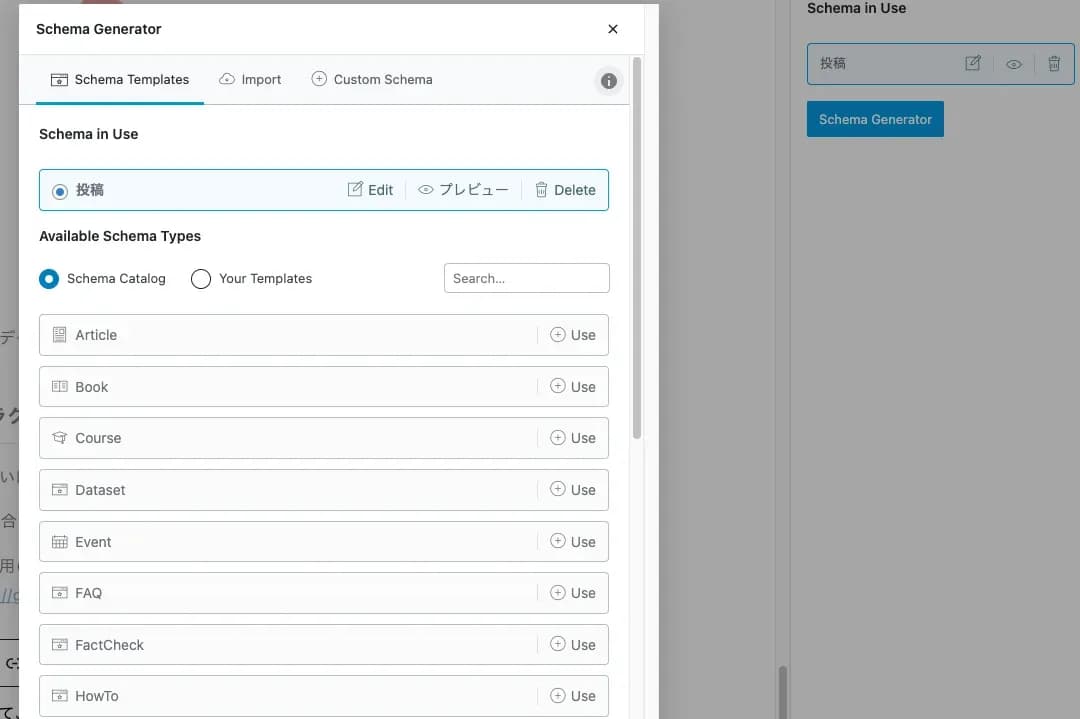
ページ別に使用することができて、使用したい構造化データのタイプをクリック・簡単な入力をするだけで挿入ができます。
※ただし、プラグインで構造化データを挿入するにしても、記述方法や必要な項目を理解しておく必要があります。
構造化データが間違っていないかテストする場合
なんとか調べて書いても、「作ってみたものの、これで良いの?間違っていない?」と思いますよね。
一度作成した後は、リッチリザルトツールを用いて誤りがないか確認してみましょう。
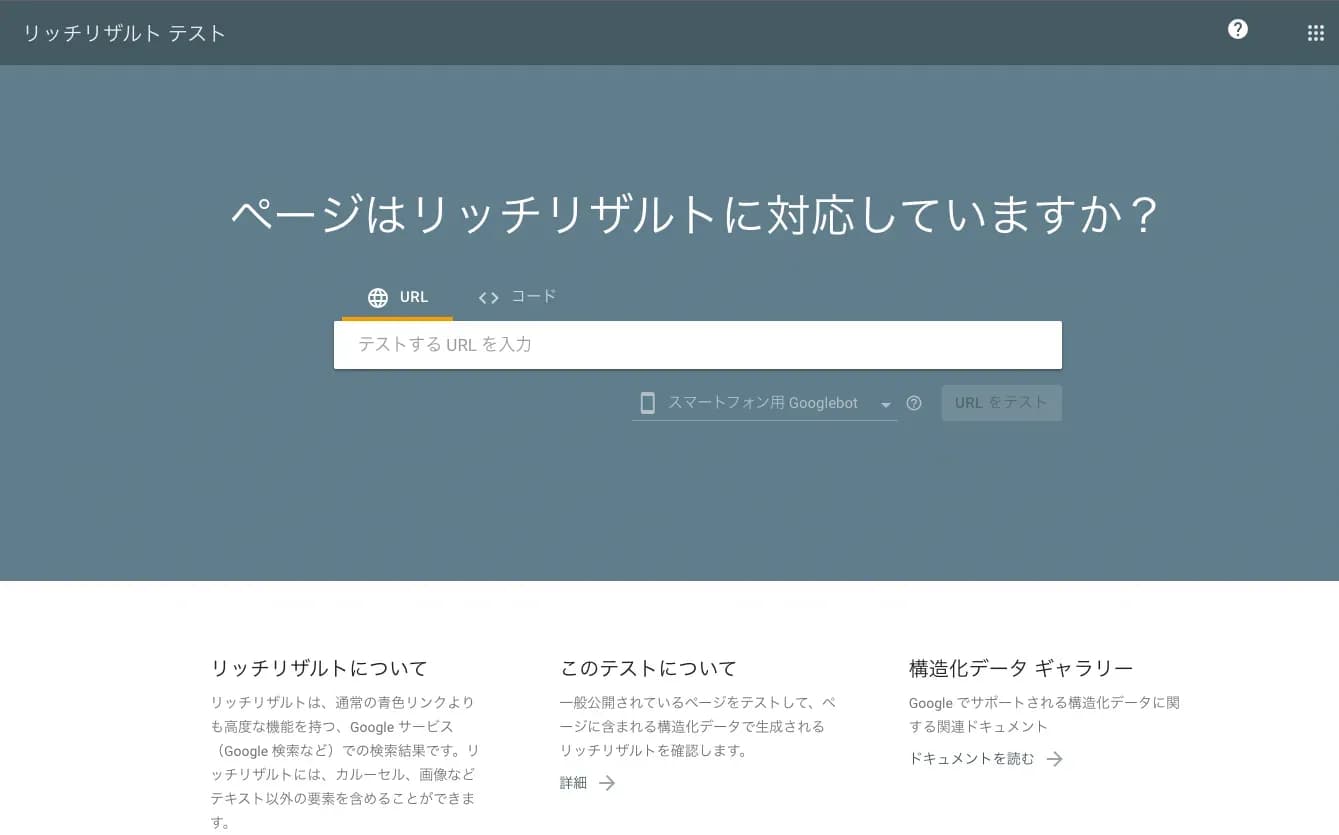
構造化データの、コードか挿入したURLを入力してテストを開始すると、構造化データに誤りがないか確認してくれます。
問題がない場合は、緑色の文字で「◯件の有効なアイテムを検出しました」と表示されます。
エラーがある場合は、赤文字で「一部のマークアップがリッチリザルトの対象ではありません」と表示されます。そのまま確認していくと、問題のある箇所が赤いマーカーでハイライトされますので、確認して修正を行いましょう。
構造化データを活用して、セマンティックなWebを意識しましょう。
言葉やイメージから小難しい印象が強い構造化データですが、記述する形式には一定のお決まりがあります。自身で記述する際は、構造化データマークアップ支援ツールやリッチリザルトツールを活用しましょう。ワードプレスの場合はプラグイン等で簡易的にマークアップが可能です。
記事を読んで不明な点等がありましたらお気軽にTwitter(@kaznak_com)などでご質問ください。 ではまた。

監修者紹介
中村 一浩
代表取締役CEO
株式会社ココログラフ 代表取締役CEO。1982年生まれ。高校卒業後に携帯販売業界にて、インターネットとハードウェアの急速な進化に触れた後、ウェブの面白さに惹かれ、2009年に株式会社ジオコードに入社。SEOを中心にウェブマーケティングを学び、同時にウェブ制作部門、システム開発部門のマネジメントも兼務。幅広いウェブ運用知識を有する。2018年に独立・起業し、検索エンジンだけでなく検索ユーザーにまで最適化する、SEOの上位互換サービスSUOを提供。SEO / SUOの独自レポートツール、サチコレポート開発者。著書『現場のプロが教えるSEOの最新常識』
■得意領域
ウェブサイト改善 / SEO対策 / コンテンツマーケティング
