
Google Search Consoleを利用していると、「『インデックス カバレッジ』の問題が新たに検出されました」というメールが届くことがあります。
今回は「送信された URL が robots.txt によってブロックされました」というエラー原因と改善方法について解説していきます。
インデックスカバレッジについてはこちらも参照して下さい
インデックスカバレッジの問題が新たに検出されました の通知と対処法

このページに書いてあること
送信された URL が robots.txt によってブロックされました
このエラーは、URLがrobots.txtに含まれていることが原因であることが多いです。
簡単にまとめると、
あなたが検索エンジンにサイトを巡回するように頼んだ(サイトマップの送信)のにも関わらず、検索エンジンに巡回されないような設定(robots.txtの記述)を行なっているので、正常に巡回できなかった
という状況です。
robots.txtとは、収集されたくないコンテンツをクロールされないように制御するファイルです。これにより検索エンジンのクローラーに自サイトにとって重要なコンテンツを中心にクロールさせたり、クロールが不要な部分についてはクロールをブロックしたりすることが可能です。

送信された URL が robots.txt によってブロックされましたの改善方法
WordPressをお使いの方はまず、WordPressの管理画面左サイドメニュー[設定]>[表示設定]を開きます。
すると画像の「検索エンジンがサイトをインデックスしないようにする」という部分を探してください。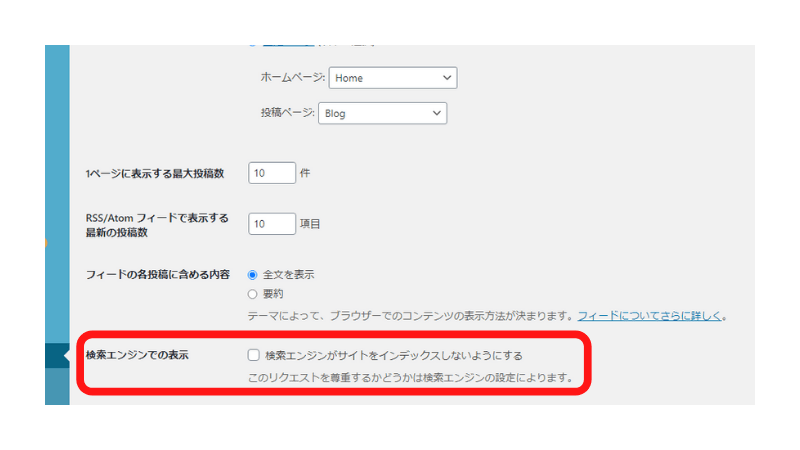
Webサイトを創設して日が浅い、もしくはコンテンツが少ないと「コンテンツや記事がまだ十分ではないから検索されないようにする」といった意図でチェックしていることが多いです。
なので、この項目にチェックが付いている場合はチェックを外しましょう。
次に、技術的な部分が分かる方に確認していただきたいポイントは robots.txt 内の「Disallow」の記述の部分です。
Disallowという記述はアクセスの拒否を行う際に使用します。
▼Disallowの記入例
Disallow : / →サイト内の全てのページをブロック(/はTOP配下全てを表す)
Disallow : →ブロックなし
Disallow : /directory1/page1.html →ページ(/directory1/page1.html)のみブロック
Disallow : /directory2/ →ディレクトリ(/directory2/)配下全てのページをブロック
Allow : /directory2/page1.html →ページ(/directory2/page1.html)のみクロール許可
このようにクロールの必要が無いページに対しては、Disallowを記述し、クロールの制御を行いましょう。よく行われている例としてはログインURLなどが対象になります。Wordpressの管理画面のURL(例123.com/wp-admin)をクロール拒否しているサイトは多数あります。
robots.txtの内容がちゃんと意図したものになっているかを確認し、サイトマップもしくはrobots.txtを修正して矛盾を解消しましょう。
そもそもrobots.txtとは?
robots.txtとは、収集されたくないコンテンツをGoogleといった検索エンジンによってクロールされないよう制御するファイルを指します。
一般的にはクローラーからクロールされることは良いと捉えられることから、「WEBページにある全てのコンテンツはクロールされた方がいいのでは?」というお話もあり、一概に正解不正解はありません。
ですが、登録をしている方のみ限定のコンテンツやショッピングカートなど、もしくはシステム的にどうしても自動で生成されてしまう重複ページなどはクロールさせることで、かえってサイト全体のSEOに影響が出ることがあるのです。
robots.txtの記述内容
主に、robots.txtは以下の要素から成り立っています。

先ほどお話をした「Disallow」の後に特定のページの場所、もしくは「/」(サイト全体を表す)が入っている場合は、そのページ(サイト全体)を検索エンジンに巡回させない設定になっているので、注意してください。
robots.txt作成時に注意すべき点
便利だし、大切なのはなんとなく分かったけど、どんなことに気をつけたらよいのでしょうか?
クロール拒否はnoindex目的で使用してはいけない
クロール拒否はnoindex(インデックスされない)目的で使用してはいけないことです。あくまでクロール拒否はクロールを拒否する役割であり、インデックスが防げるわけではないためです。
robots.txtにdisallowの指定をすると、クロールのアクセスを制御することができるため、基本的にはインデックスされることはありません。
しかし、他ページにdisallow対象のページへのリンクが設置されている場合に、インデックスされてしまう可能性があります。
クローラをブロックしているページでも他のサイトからリンクされていればインデックス登録が可能
Google では、robots.txt でブロックされているコンテンツをクロールしたりインデックスに登録したりすることはありませんが、ブロック対象の URL がウェブ上の他の場所からリンクされている場合、その URL を検出してインデックスに登録する可能性はあります。そのため、該当の URL アドレスや、場合によってはその他の公開情報(該当ページへのリンクのアンカー テキストなど)が、Google の検索結果に表示されることもあります。特定の URL が Google 検索結果に表示されるのを確実に防ぐには、サーバー上のファイルをパスワードで保護するか、noindex メタタグまたはレスポンス ヘッダーを使用する(もしくは該当ページを完全に削除する)必要があります。
ですので、インデックスをさせたくないページにはページのhead内に
noindexを促すrobotsメタタグ
meta name="robots" content="noindex" Code language: JavaScript (javascript)のように記述するかプラグイン等でnoindexの設定をしておきましょう。
重複コンテンツの正規化に利用しない
同じようなお話になりますが、重複コンテンツが発生している場合、robots.txtで片方のコンテンツページをブロックすれば重複コンテンツを正規化できると考える方がいますが、それは正しい方法ではありません。
重複コンテンツの場合は、canonicalや301リダイレクト、文章のリライトなど正しい方法で正規化すべきです。
処理の優先度は上から下ではない
少しテクニカルなお話ですが、robots.txtの処理の優先度は下記の二つを覚えておいてください。
・階層が深い方から処理される
・AllowがDisallowより優先される
例を挙げてみてみます。
User-agent:*
Disallow: /shop/tokyo
Allow: /shop/
この処理だと、下記処理のように見えますが違うんです。
・/shop/tokyoへのアクセスを禁止!
・やっぱり/shop/以下は全部入ってもいいよ。
このケースでは「/shop/tokyo」の方が深い階層にあります。
ですので、後から上の階層(/shop/)に対する「Allow」の処理を書いても階層が浅いため優先度が低く、処理されないということになってしまします。
まとめ
いろいろとお伝えしてきましたが、やはりrobots.txtの扱いは慎重に行いましょう。
クローラーが全ページアクセスできなくなってしまったら、順位が急落することもないとは言えません…
robots.txtそのものは簡単に作成できますので、その分怖いファイルとも言えます。
ですが、Web担当をやっていれば触れることも結構あるファイルになるのである程度の理解はしておきましょう。
わからない点はお気軽にご相談ください
急に警告メールが届いて不安に思った方もいらっしゃると思います。
この記事が多少なりとも、お役に立てばと思います。
記事を読んで不明な点等がありましたらお気軽にTwitter(@kaznak_com)などでご質問ください。
では失礼します。





